





写在前面:
Nvidia-driver、CUDA、pytorch、Ubuntu你们有一个算一个,全都是我的一生之敌。。。我把你们全鲨了。。。
最近由于科研需求,在学习3D Gaussian Splatting相关的内容,并有尝试跑源码,本来是在Windows系统下跑通了Gaussian Splatting的源码,后续想跑Gaussian Shader的时候,发现依赖里很多包都是只有Linux有的。原文作者的环境应该是在Linux下的,因此在自己的设备上装了Linux双系统,在实践的过程中遇到了很多百思不得其解的问题,多次重装,故在此记录,望能帮助有缘人。(感谢我的舍友张同学和我的同门唐同学对我的指导和帮助,鞠躬.gif。)
3D Gaussian Splatting环境配置过程(Windows下)
3D Gaussian Splatting的环境非常好配置,因为所需的依赖非常少且干净,只需要照着下面提供的参考资料视频逐步操作即可。我的电脑配置是:RTX 4090 + CUDA 11.8,environment.yml中给定的环境是py3.7 + pytorch1.12.0-cuda11.6,一开始其实CUDA版本没有对应,但是跑代码本身没有问题,GPU调用也非常正常,CUDA toolkit应该是在编译时才会使用。
后来重新装了一遍cuda11.6,对于cudnn库,我看到conda环境中的pytorch是: py3.7_cuda11.6_cudnn8_0,因此其对应的cudnn应该是8.0,但是官网的cudnn只有8.2.0及以上有对应cuda11.6的版本,因此我安装的是cudnn8.6.0。
- 3D GS Source Code: https://github.com/graphdeco-inria/gaussian-splatting
- Windows环境配置参考资料:
- https://www.youtube.com/watch?v=UXtuigy_wYc
- https://github.com/jonstephens85/gaussian-splatting-Windows
从数据处理到训练和测试的过程中用到的指令集:
- ffmpeg -i ./David.mov -qscale:v 1 -qmin 1 -vf fps=10 %04d.jpg (其中./David.mov是我自己拍摄的视频路径)
- python convert.py -s C:\LPY\GassianSplatting\dataset_self\David01
- python train.py -s C:\LPY\GassianSplatting\dataset_self\DavidWide01
- SIBR_gaussianViewer_app.exe -m C:\LPY\GassianSplatting\gaussian-splatting\output\120f6889-4
Gaussian Shader环境配置,及Ubuntu+windows双系统诸多排雷记录
这部分光前前后后各种卸载重装解决问题就消耗了我四天的时间,期间多次情绪崩溃(想摔电脑的程度sos),好在最后终于得以解决。
我最后用的配置如下:
- RTX 4090
- Nvidia-Driver 525
- Cuda Toolkit 11.6
- Anaconda 2023.03
- Python 3.7
- torch1.12.0+cu116
- torchaudio0.12.0+cu16
- torchvision0.13.0+cu116
一些常用基础的Linux控制台指令
- cd 跳转到某路径
- ls 显示该路径下所有文件及文件夹
- cp A B 拷贝A到B,直接写到文件名
- mv A B 移动A到B,同上
- sudo 管理员权限,任何时候报错说没有权限都可以试试在前面加这个
- sudo apt install Ubuntu最重要的装包指令,缺啥装啥。
部分submodule及其安装方式
首先需要说明的是:GaussianShader的原作者似乎没有清理环境文件,感觉是linux下直接导出的,因此不确定有一些依赖是否没有用到,这部分时间原因不再深究,但是该项目用到了一些其他的项目,而这些是无法直接用conda安装找到的,包括:
- diff-gaussian-rasterization
- simple-knn
- nvdiffrast
- cutlass
其中,前两个在clone仓库时就会作为submodule下载下来,只需要cd到其路径下,pip install .即可。nvdiffrast和cutlass需要自己去github上找到并下载,再使用pip install .安装。另外,cutlass我没有找到依赖中显示的0.0.1版本,最早的只找到了0.1.0。但是最后我没装好像目前代码跑起来也没有什么问题。 - Nvdiffrast地址:https://github.com/NVlabs/nvdiffrast
WSL尝试
一开始畏难不想装双系统,尝试使用了WSL(Windows下的Linux,后来我觉得非常坑弃用了),但是发现在使用pip安装diff-gaussian-rasterization的时候会报错,具体错误为:No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda-11.8'
但是该报错中的环境变量路径是正确的CUDA路径,检查后发现nvcc -V也无法访问到CUDA,尝试在~/.bashrc中添加了环境变量,仍然没有解决问题,因此我考虑到有可能是CUDA是安装的windows版本有关系(当时的路径是正确的windows的cuda路径,此处的报错只是一个示例),我上官网进行了查询,发现WSL有一个单独的CUDA版本。因此我换用了WSL专用的CUDA,这次nvcc -V可以正常访问,但是diff-gaussian-rasterization仍然不能安装。这个我感觉应该是WSL自己的锅了,后续请教了一下我的同门,最后得出的结论是,WSL下的CUDA有一些文件与Linux版本放的位置不同,导致程序在链接的时候找不到这些文件,不能跑通,通过一个修改可以使得程度跑通(大概原理maybe是加上wsl特有的lib路径):
1 | # 源码的scene/NVDIFFREC/renderutils/ops.py下,大约在48行 |
但是上面这样的修改毕竟不是长久之计这个发现也令我两天之后终于痛定思痛地放弃了WSL,这玩意太弱智了。。。(当然也可能弱智的是我。)
投身Windows+Ubuntu双系统的怀抱
关于Ubuntu镜像文件制作
这里就是找了网上常见的教程,但是有一个很坑的点,不知道为什么我的balenaEtcher烧了几百遍就是每次烧Ubuntu20.04都失败,但是烧Ubuntu22.04就能成功,后来我换用了rufus制作镜像系统安装盘。下面是我的同门推荐的一些系统盘制作软件:
- balenaEtcher
- rufus
- UltraISO
Windows进行磁盘分区
这里我用的是Windows自带的计算机管理里面的磁盘管理,但是也可以用DiskGenius这个软件,可视化效果好一点。我这里是直接分出了800个G给Ubuntu。双系统安装方式
具体的安装方式就是插上制作的系统U盘,关机重启,启动的时候狂按delete(不同主板可能不一样),进入Bios之后把U盘设为开机启动项,然后保存并推出,再次重启就会自动开始Ubuntu安装过程(具体的设置下面会描述)。Ubuntu和CUDA版本对应问题
一开始装Ubuntu直接上网下了个最新的22.04。然后我库库一通装完了之后发现GaussianShader里面的里面的依赖cuda版本是11.1,然后我库库打开CUDA官网,库库选,选到Version我愣住了,我真的愣住了。如下,CUDA 11.1没有Ubuntu22.04版本。坑的要死,谁懂那种好不容易装好了Ubuntu之后发现没有对应CUDA版本的死亡感觉。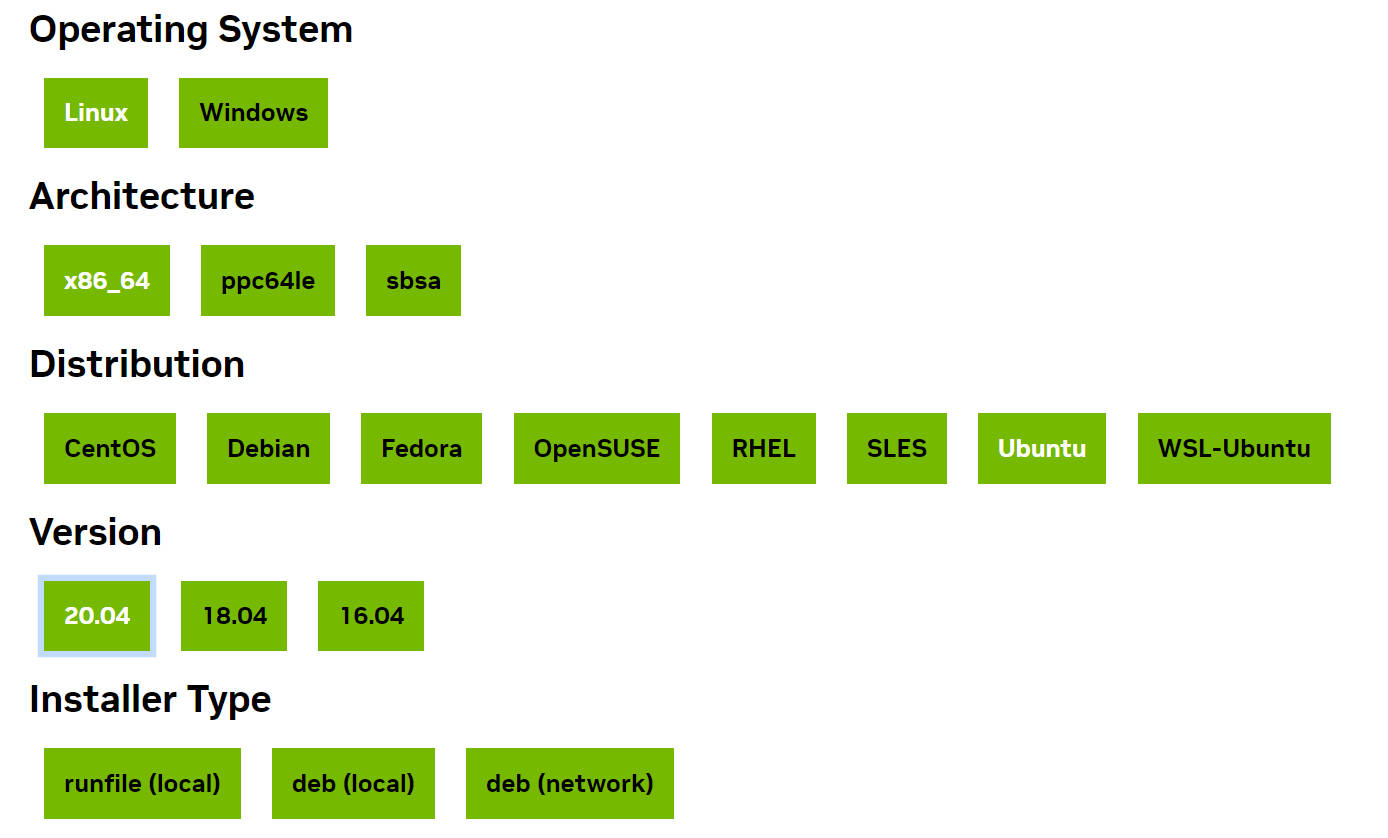
疑似4090算力不支持低版本CUDA问题
试图换用Ubuntu20.04,我苦苦进行了以下组件的安装,发现代码就是不能跑(这里是我的失误,报错没记下来),后来发现或许是因为cuda11.1版本太低,算力支持不匹配,在4090上会有问题(真的呕吐了),如下图:(因此我后续直接放弃了CUDA11.1,把依赖里面的pytorch相关全部注释掉,回头自己装。)
然后我试图用回Ubuntu22.04,配置过程如下
- 先装Ubuntu22.04
- 检查nvidia-smi,能调用到显卡。
- 装Clash梯子。
- 装anaconda。
- 装git
- git clone
- 下载example data并放在对的位置
- 把环境里面的子模块(上文列出的那四个)还有pytorch注释掉,然后
conda env create --file environment.yml - 安装cuda toolkit 11.8,报错,出现的问题跟这个链接中一样:https://forums.developer.nvidia.com/t/cant-install-cuda-11-8-on-ubuntu-22-04-lts/263227,这个问题后续我认为是因为Ubuntu上面已经有了一个更高版本的Nvidia显卡驱动所导致的。
- 尝试重装nvidia-driver,无果,根本看不懂报错,是我太菜了。
- 尝试重启大法,但是最让人崩溃的来了,重启之后Ubuntu无论如何都连不上网了,右上角的网络图标也没有了,更弱智的是设置里面Network那一栏连Wired这一栏都没有了,但是重启进Windows一切都很正常,很难理解,插拔网线也没有用,这个问题我查了很多资料,也求助了同门,最终也没有解决,没有网络一整个就是什么都无法操作的状态。(后来我认为这可能跟我频繁地开关Clash的全局代理,并且Ubuntu重启的时候没有关闭Clash全局代理有关系,具体什么关系我就真的不得而知了。所以看到这里的朋友,慎用Clash,慎开着全局代理重启,原因我也无能为力。)后面我叫天天不应,叫地地不灵,只能重启进Windows,用DiskGenius暴力删除所有Ubuntu的分区,以及Ubuntu开机启动项,重新安装Ubuntu。卸载Ubuntu这件事也可以参考这个链接:https://blog.csdn.net/qq_42257666/article/details/120721561
最终回,Ubuntu20.04
接上文,最终因为一些稳定性的考虑,还是使用了Ubuntu20.04版本。这也是最终成功的版本,配置过程如下:
安装Ubuntu 20.04 Desktop
制作镜像参考上文,安装过程选择参考:https://blog.csdn.net/wyr1849089774/article/details/133387874。但是有两点需要注意:
安装的时候没有让Ubuntu安装显卡驱动,也就是这里没有勾选最下面那个安装第三方软件。
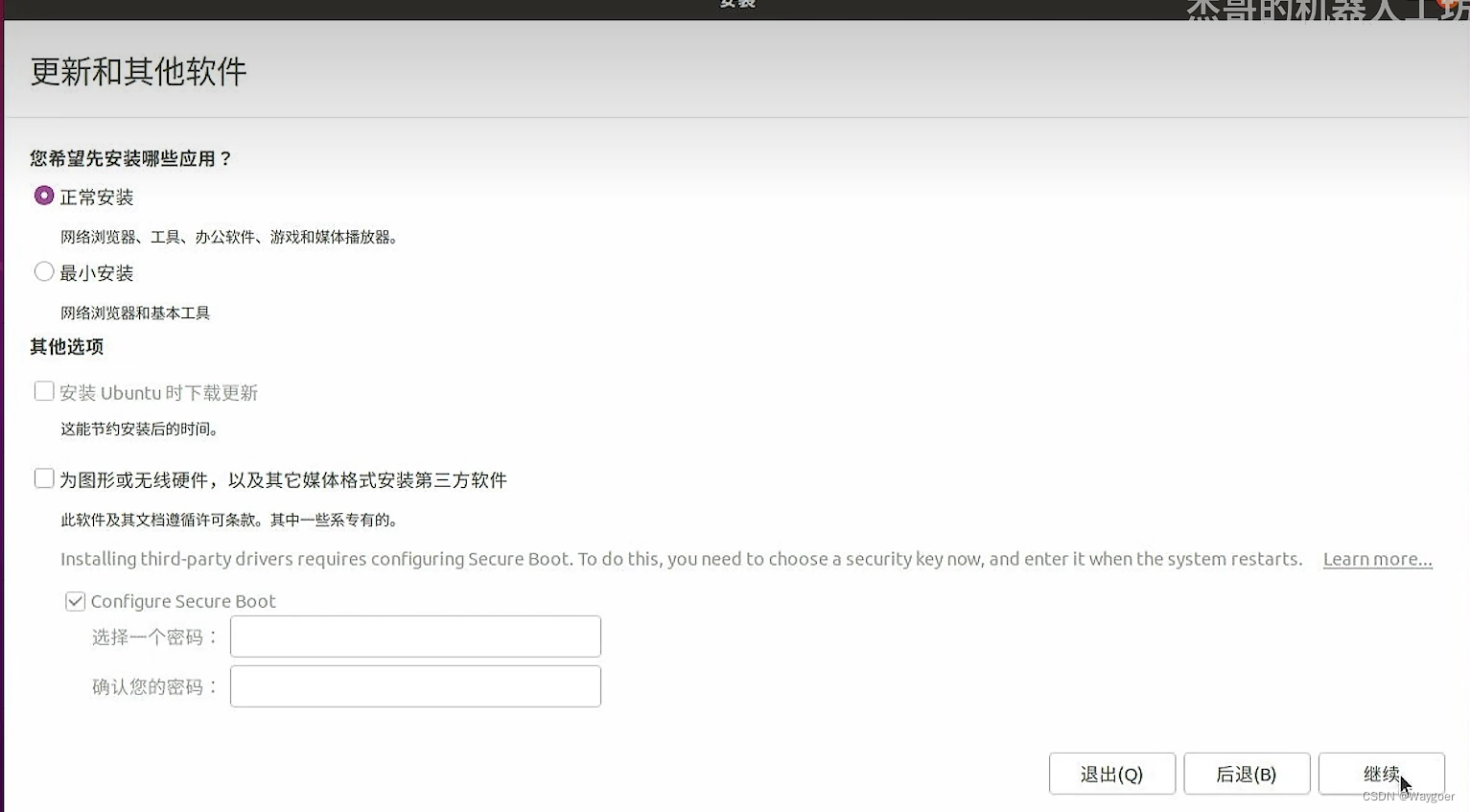
安装的时候选择与Windows并存。这里也导致我重装了一两次Ubuntu,因为之前按照网上的教程单独分区,总有些区用着用着就报low disk space(有一次报的是根目录,有一个报的是/boot),但是这样直接选共存,会所有的都在同一个连续的储存中,不会出现某一部分空间不足(如下图,选第一个)。
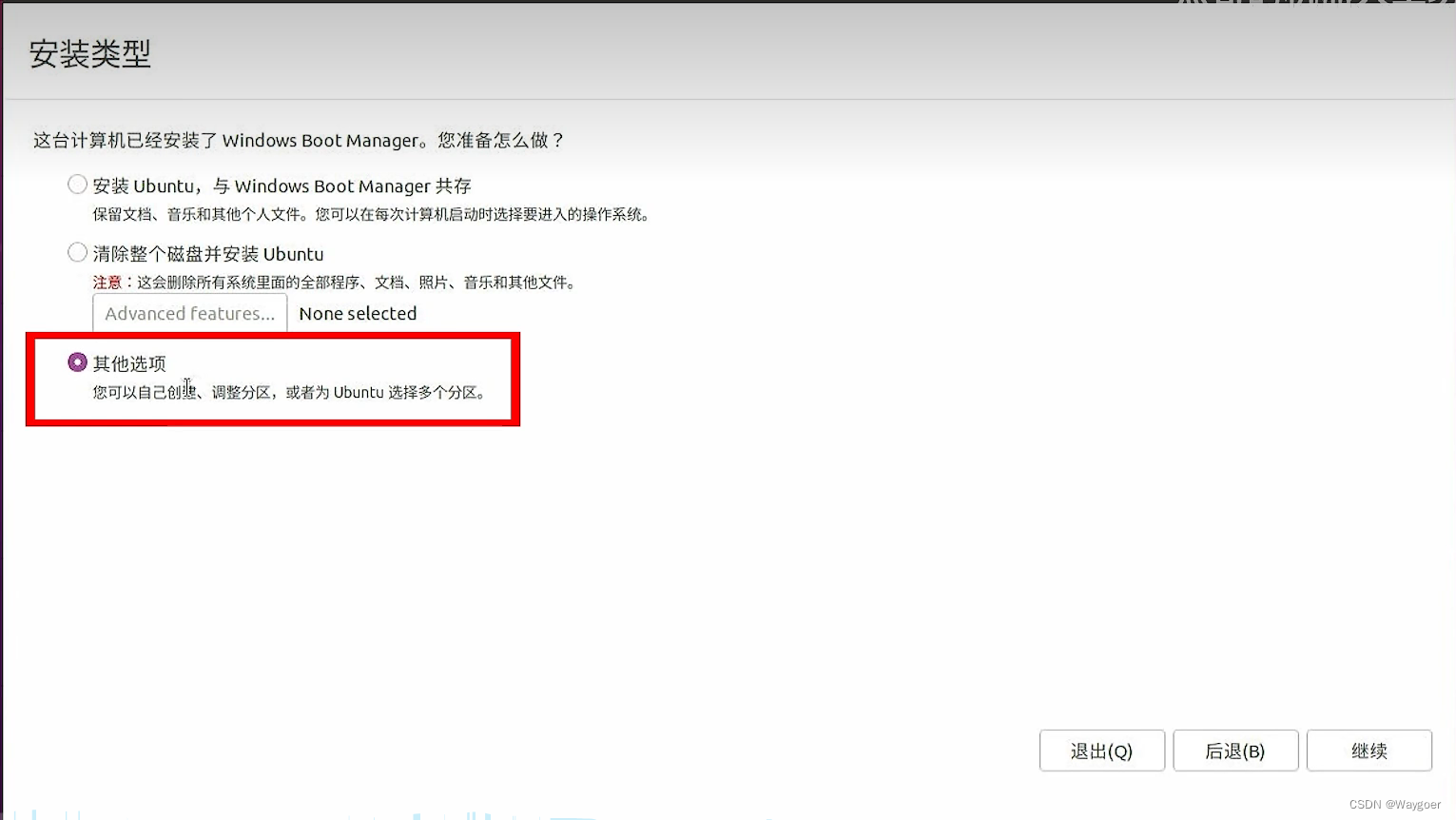
换源
换用国内的清华源,以免网络问题导致无法安装包。
- 换源过程参考:https://blog.csdn.net/qq_42620328/article/details/116313697
- 清华镜像站Ubuntu官网:https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/,可以在上面copy配置文件内容。
安装CUDA
因为cuda遇到的问题比较多,我这次直接先装CUDA,避免之后辛辛苦苦装了别的又前功尽弃。安装的版本是CUDA Toolkit 11.8,安装命令去官网选择自己的配置之后会直接给出,该过程会自动安装520版本的显卡驱动,nvidia-smi可以正常访问到显卡,但是nvcc -V需要自己配置环境变量。具体配置过程为,用sudo gedit ~/.bashrc命令打开.bashrc文件(没有gedit的话用sudo apt install gedit装一下就好了),然后在最后添加CUDA环境变量信息,我添加的是(需要改成自己的CUDA版本和安装路径):
1 | #cuda version |
- CUDA安装指令的话直接浏览器搜索CUDA加对应版本一般跳出来第一个就是,比如CUDA11.6的官网下载地址为(已经选了我的配置):https://developer.nvidia.com/cuda-11-6-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=20.04&target_type=deb_local
安装Anaconda
Anaconda这里我直接去镜像站下载了.sh安装文件,然后在控制台sudo bash xxx.sh安装。用最新版不行,无论如何配置环境变量控制台都找不到conda,最后用的是2023.03版本。
安装Clash
Clash最新版1.3.8也不行,直接就是一个安好了打不开,死活打不开。最后用的是Clash1.3.6。
Clash官方Git仓库地址:https://github.com/zzzgydi/clash-verge/releases
控制台科学上网
关于挂梯子代理的问题,请教了同门之后发现控制台和GUI是两个分开的代理,如果只用GUI的Clash开启代理,控制台是访问不到的,因此最后使用了这个链接里面的第四部分,每次打开控制台人为使用proxy和unproxy指令进行代理的开关(这里的127.0.0.1指的是本机,端口号要看clash里面的设置):https://www.joeyne.cool/http/proxy/ubuntu-%E5%AE%89%E8%A3%85clash%E5%B9%B6%E9%85%8D%E7%BD%AE%E5%BC%80%E6%9C%BA%E5%90%AF%E5%8A%A8/
安装ibus中文输入法
安装好了之后在设置里面找不到拼音输入,重启解决问题。
参考:https://zhuanlan.zhihu.com/p/132558860
Ubuntu黑屏问题
重启的时候发现ubuntu不能重启,黑屏无法显示桌面,该问题应该是由于CUDA带着安装的Nvidia显卡驱动版本太低,和Ubuntu的内核版本不匹配导致的。暂时的解决方案如:https://www.cnblogs.com/masbay/p/10718514.html (这里最终我觉得还是改装合适的显卡驱动版本一劳永逸,后面有相关内容)
Conda安装环境
依旧像之前那样,注释掉所有的子模块(上文列出的那四个)还有pytorch。结果发现安装时前面的依赖安装都很顺利,后半部分pip那些包装不上,每次都。。。进行一个断网,后来发现就是因为open3D和scipy太大了,老是会响应时间太长然后直接中断了然后断网。因此把pip安装的依赖复制出来做成txt,使用pip install -r requirements.txt命令单独安装。并对最大的open3D这个包单独用-i加了清华镜像来下载。这里如果自己的梯子还不错的话也可以考虑设置pip install some-package --default-timeout=100,增大pip的响应时间。
安装Pytorch
Pytorch官网:https://pytorch.org/get-started/previous-versions/
这一步也是究极折磨,根本原因是用的4090显卡太新,但是GaussianShader的原装环境太旧。我一开始根据算力支持表准备选用Pytorch2.0.0+CUDA11.8,conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia,但是安装报错,告诉我需要把python升级到3.8。
1 | UnsatisfiableError: The following specifications were found |
然后我试图使用conda安装python3.8,这下完蛋了,限制更多了,原始环境里面的很多包都不支持更高的python版本,我又不太敢直接全升级,到时候出问题更麻烦。于是我采取了死马当活马医的遍历方案,从pytorch2.0.0依次往下捋,撞大运,好在最后给我撞到了。
最后用的pytorch版本是:torch1.12.0+cu116 torchaudio0.12.0+cu16 torchvision0.13.0+cu116,但是我服务器下载还是好慢,难评,最后我直接本机挂代理下载了whl文件之后用scp传输到服务器进行安装的,不过这个maybe是我的网络设置不太合适。下载位置:https://download.pytorch.org/whl/cu116/torch/,直接```wget https://download.pytorch.org/whl/cu116/torch-1.12.0%2Bcu116-cp37-cp37m-linux_x86_64.whl```即可下载,后面的那个填包的链接。wget下载还是比较稳定的,就算中间断网也会自动断点续上。
安装四个子模块
安装方式很简单:直接cd到这个包的路径下,然后pip install .就ok。注意有一个问题是,这几个submodule的安装似乎是依赖于pytorch版本的,总之每次换了pytorch版本都要uninstall再install重新来一次。但是我在上面的操作全部进行完之后发现安装报错,这应该是由于没有装cuda11.6,如果有遇到类似报错可以检查一下自己的cuda和pytorch是否对应,安装CUDA11.6的方式就像之前一样直接去官网选择然后命令一行一行复制进控制台就行。报错如下:
1 | No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda-11.8' |
Ubuntu继续黑屏,升级显卡驱动
这次黑屏连之前那个进recovery模式的方法都没用了,全部黑屏,看来还是不能一时走捷径,SSH可以连上服务器,证明其开机应该没有问题,只是图形界面无法显示,这必然是nVidia显卡驱动的问题,nvidia-smi报错:Failed to initialize NVML: Driver/library version mismatch。查了一下之后发现Nvidia的显卡驱动版本可以高于CUDA的版本,也就是说我可以在保持CUDA11.6的基础上换用更新的,和Ubuntu内核可以匹配的Nvidia驱动版本。因此我重新装了Nvidia-driver 525,指令如下(用这个指令是因为一开始直接用apt install会报依赖不存在,需要自己手动安装好多依赖包,但是这个aptitude可以自动安装依赖):
- sudo apt install aptitude
- sudo aptitude install nvidia-driver-525
- 此时nvidia-smi依旧报错:Failed to initialize NVML: Driver/library version mismatch
- sudo reboot重启解决问题
CUDA11.6重装
但是问题是cuda似乎被他卸载了,反正现在nvcc -V是不行了。只能又重新装了一遍cuda11.6,现在一切完美。装之前可以用sudo apt install -s检查一下要安装的包里面有没有Driver,避免又重新装了个旧的显卡驱动。安装指令里面不要用-y,-y会在安装过程中需要确认的时候自动回答yes。
大功告成
经过以上折磨的过程,最终终于可以用git仓库上官方提供的train指令进行训练了,此处贴一个半夜两点多终于开始训练的照片,以表纪念。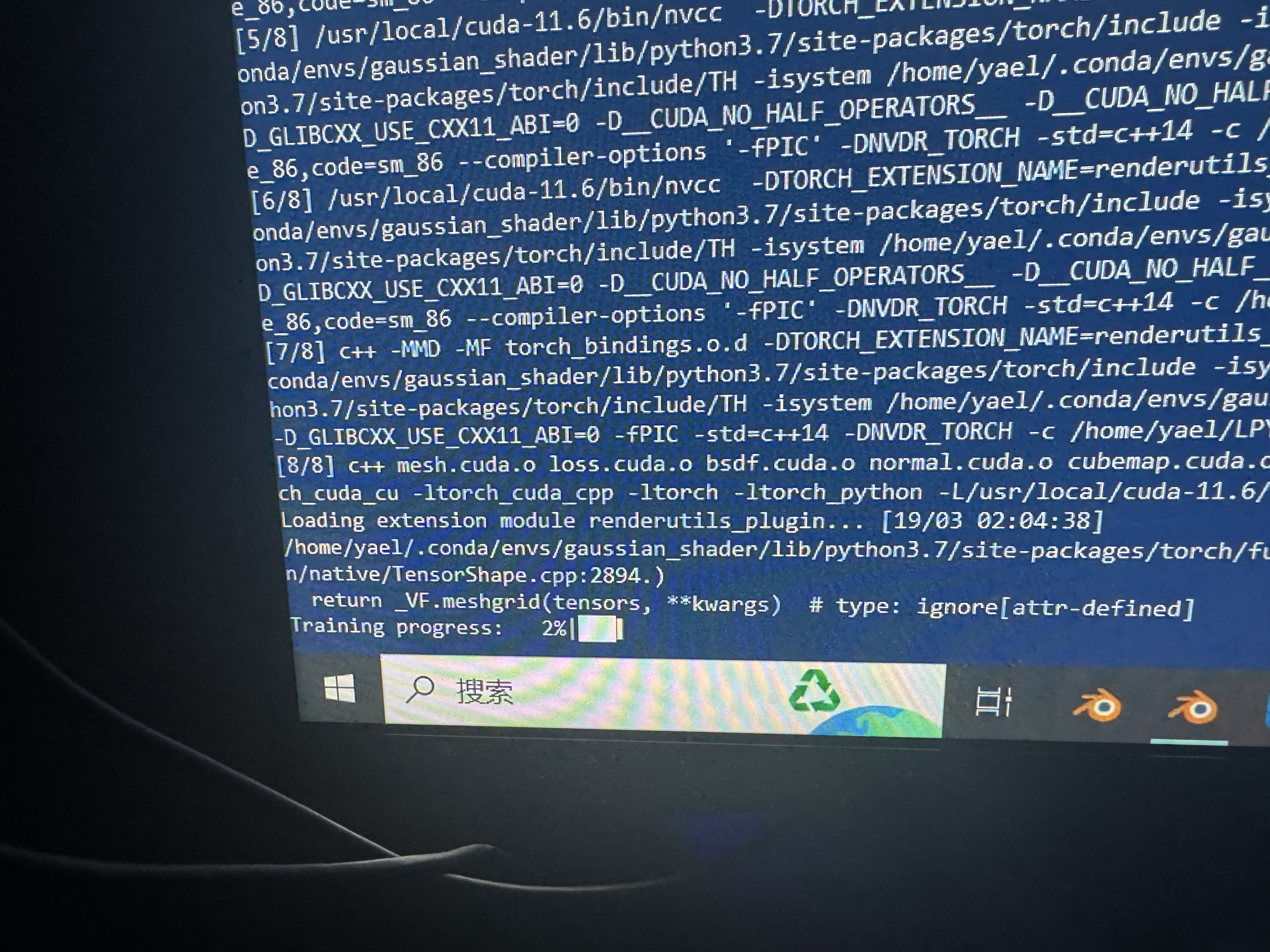
后续设置
- 后面的话在舍友和同门的建议下直接用本机vscode + SSH控制服务器,速度很快,也不需要另外的屏幕显示图形化界面。
- 代理也可以使用本机的代理地址,把~/.bashrc里面的ip改掉就好。
补充说明
后续在Ubuntu上重新配置了一遍gaussian splatting的环境,首先,Gaussian Shader的环境在我的电脑上是不能直接给gaussian splatting使用的,其次,我直接conda create env的环境会遇到和这个issue一样的问题:https://github.com/graphdeco-inria/gaussian-splatting/issues/184,后续的解决方案是在新的环境的基础上自己重新安装了pytorch,具体版本就是之前和gaussian shader环境一样的pytorch,用pip安装的,conda的版本不行,不知道为什么。
Build SIBR_viewer
Build SIBR_viewers 过程中又遇到了问题。
- Ubuntu20.04自带的cmake版本只到3.16.0,SIBR_viewer需要cmake版本在3.22.0以上。cmake安装参考了知乎文章:https://zhuanlan.zhihu.com/p/519732843
- 后来遇到了报错找不到opencv的问题。使用sudo apt install libopencv-dev安装的Opencv显示最高版本为4.2.0,但是我这里显示SIBR_viewers需要Opencv4.5。Opencv的卸载和重新安装参考了(在这之前首先要根据gaussian官方给的指令进行依赖库的安装):
- https://wenku.csdn.net/answer/b8bdb73faa52437ea21d74cd0413ab54
- https://zhuanlan.zhihu.com/p/391890959
- 下一个问题是明明成功安装了Opencv,Build的时候还是找不到,这个问题我参考了网上一些方案但是没有成功解决,最终的解决方式是把opencv库从“/usr/include/opencv4/opencv2”拷贝到“/usr/include/opencv2”。
- 问题解决了,出现的新问题是找不到embree库,该库可以用官方仓库的指令安装预编译版本,也可以直接sudo apt install embree-tools,但是安装之后会发现编译仍然找不到,这个我查了非常多资料都没能解决,报错是:/usr/bin/ld: cannot find -lembree。
全局搜索了embree之后找到三个文件,分别是libembree3.so libembree3.so.3 和 libembree3.so.3.8.0,这三个文件的文件大小和hash值完全一致,我最后采取了一个非常抽象的方法,把libembree3.so复制了一份,重命名为libembree.so,就通过了。。 - 补充一点,我在~/.bashrc中export添加了 LD_LIBRARY_PATH变量,给他增加了三个值:
- home/yael/Programs/opencv-4.5.5/build/lib
- /usr/lib/x86_64-linux-gnu
- /home/yael/Programs/embree-3.6.1.x86_64.linux/lib
增加了两个embree库的位置,一个是根据github仓库的readme自己装的,一个是sudo apt install装的,至于是哪个起的作用,我目前实在没有力气去深究了。
- 这些都解决后编译仍然报错,报的是undefined reference to
cv::calcOpticalFlowFarneback等很多的undefined reference to,查了很多资料已经没能解决,最后我看到一篇博客里面说opencv的video模块依赖ffmepg,警觉自己没有安装ffpeng,于是sudo apt install了ffmpeg,然后到opencv的安装路径下,uninstall再重新编译重新install,然后再次尝试编译SIBR_viewer,终于万事大吉。
重新安装Opencv+Opencv Contrib
后来编译好的SIBR_viewer被我搞崩了,原因是我把之前装的opencv4.2给删干净了,才发现viewer跑不了了,之前好像用的4.2,至于为什么4.2也可以我就不得而知了,但是又重新安装了一边Opencv4.5.5。安装好之后本来一切顺利,但是发现build的时候报错找不到ximgproc,查找资料之后发现这是一个单独的模块,存在于Opencv Contrib里面,而我只装了Opencv本体,只好重装。
首先彻底卸载Opencv,包括自己编译的版本和sudo install的版本,卸载参考:
- https://blog.csdn.net/m0_73694897/article/details/129175515
安装步骤如下: - 参考资料:
- 下载opencv 4.5.5和opencv_contrib4.5.5,注意一定要版本对齐,这里笔者之前因为contrib没有版本对齐,无法成功编译。放的路径就是opencv和opencv_contrib分别一个文件夹就行。
- cd opencv
- sudo mkdir build
- cd build
- cmake -DOPENCV_EXTRA_MODULES_PATH=../../opencv_contrib/modules .. -D CMAKE_BUILD_TYPE=Release -D OPENCV_GENERATE_PKGCONFIG=YES
- sudo make -j4
- sudo make install
查看是否成功安装:
opencv_version
pkg-config –cflags opencv4
pkg-config –libs opencv4
不加opencv后面的4找不到,本来网上有个帖子可以把opencv4.pc重命名为opencv.pc解决这个问题,但是我没用也成功编译了,pkg-config –cflags opencv报错如下:
1 | Package opencv was not found in the pkg-config search path. |
安装完opencv之后又重新去编译SIBR_viewers,编译正常无报错,但是运行的时候报错找不到uv_mesh.vert,解决方案是在这篇issue上找到的: